亂碼

 Clash Royale CLAN TAG#URR8PPP
Clash Royale CLAN TAG#URR8PPP 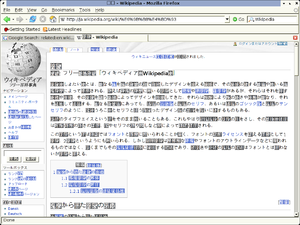
網頁呈現亂碼現象
頁面:日文維基百科條目《書体》
對應於中文維基百科條目《字體》
乱码指的是電腦系統不能顯示正確的字符,而顯示其他無意義的字符或空白,如一堆ASCII代碼。这样所顯示出來的文字統稱為亂碼。[1]
乱码是因为「所使用的字符的源码在本地计算机上使用了错误的显示字库」,或在本地计算机的字库中找不到相应于源码所指代的字符所致。不同国家和地区的文字字库采用了相同的一段源码,或是源文件中因为文件受到破坏,致使计算机默认提取的源码错误,或是计算机没有安装相应字库,都有可能产生乱码。
例如,微软编译器产生“烫烫烫”“屯屯屯”乱码,编码字符集转换产生的“锟斤拷”“毺絞銝”“脣銝餌”乱码。[2]如果是台湾(BIG-5)会显示“昍昍昍”,日本(Shift-JIS)会显示“フフフフフフ”。
目录
1 可能的產生原因
2 可能的解決方法
3 参見
4 参考
5 外部連結
可能的產生原因
- 一般是軟件程序解碼錯誤。如瀏覽器把GBK碼當成是Big5碼顯示,或電子郵件程序把對方傳來的郵件錯誤解碼。如果在發送時編碼錯誤,收件者的電郵程序是不能解碼的,需要寄件者的電郵程序重新編碼再寄。
字體檔案(font file)不對。
- 來源編碼錯誤,或文件受到破壞。
- 一种语言版本的操作系统安装了另外一种语言版本的应用程序,或者应用程序安装的补丁的语言版本与应用程序原来安装的语言版本不一致。
- 早期单字节的应用程序在打开双字节语言的文件时不能正确识别文字的分割,在换行的地方把一个字从中分成两段,导致紧接在后面的整个一行全部都是乱码。
- 低階版本的应用程序不能识别高階版本的程序创建的文件。
可能的解決方法
- 轉換編碼。一般可試Big5、GBK、UTF-8(Unicode的一種應用方式,包括世界上主要的文字)三種,如涉及的不是中文,可以再試JIS(日文)、KR(韓文)及其他文字編碼。徹底的解決方法是雙方使用同一編碼系統,如UTF-8,只要用戶有對應的字體檔案就可以正確的顯示文字。實際上要統一編碼系統還要克服各種客觀的困難,現時只有靠軟件(如Microsoft AppLocale)有更高的解碼能力。
- 轉換字體。如果解碼正確而出現錯誤文字,有可能是字體檔案中沒有相對應的字符,可嘗試轉換字體檔案。
- 如果本來該顯示出漢字的,卻變成數字,如最欣賞相中拉(最欣賞相中拉)等Unicode代碼,可以把這部分抄出來,獨立存儲成html檔, 再用瀏覽器打開解碼。或可以直接使用JavaScript作解讀︰
alert("最欣賞相中拉");
- 其他。有時解碼的方法要視乎軟件和實際環境,及不斷嘗試才能解碼,特別在不知本來是用哪種編碼系統時。
- 有時輸入漢字時也會出現亂碼,不過這種情況很少出現。最大的原因是輸入法所用的編碼,與經編輯器輸出的字體編碼不符所致,可嘗試轉換字體來解決。例如把GBK編碼的輸入法裝到只支援Big5的系統上,是不能正確顯示所輸入的字的;必需選擇Big5編碼的輸入法,或把輸入法裝到GBK的系統中。
- 有關外文所引致的亂碼,只有轉換支援某外文的字體檔案才能解決。
参見
編碼(encode)
解碼(decode)
字體檔案(font file)
外字(UDC)
香港增補字符集(HKSCS)- 中文亂碼
- Microsoft AppLocale
参考
^ Schäfer, Ingo. Premodern Chinese Written Language, an Introduction. [永久失效連結]
^ 红猴子. "烫烫烫屯屯屯" 那些事. 知乎专栏
外部連結
- 邮件乱码
E-mail乱码解码器(简体中文)
E-mail乱码解码器(繁体中文)- E-mail乱码解码器
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||